
前言
- 全部由chatgpt生成,目前尚未考证,作为理解的一层基础以供后面辨析以及理解
背景
- 不理解依概率收敛
思维过程
- 依概率定律怎样理解
- 强大数定律和弱大数定律有什么不同
- 几乎处处收敛和依概率收敛有什么不同?描述的对象是?
- 有多少种不同的收敛方式?有什么区别?
- 强大数关注样本路径,弱大数关注概率,什么是样本路径,什么是固定 ω
强大数、弱大数
弱大数定律:
“样本均值大多数时候接近总体期望。”强大数定律:
“样本均值几乎每一条样本路径最终都收敛到总体期望。”
依概率收敛、强大数、弱大数
依概率收敛:一种收敛方式(概念)
弱大数定律:一个定理,结论是“样本均值依概率收敛于期望”
强大数定律:一个更强的定理,结论是“样本均值几乎处处收敛于期望”
| 维度 | 依概率收敛 | 弱大数定律 | 强大数定律 |
|---|---|---|---|
| 性质 | 概念 | 定理 | 定理 |
| 研究对象 | 任意随机变量序列 | 样本均值 | 样本均值 |
| 收敛方式 | 依概率收敛 | 依概率收敛 | 几乎处处收敛 |
| 强弱 | 弱 | 弱 | 强 |
| 是否涉及样本均值 | 不一定 | 是 | 是 |
| 是否是大数定律 | 否 | 是 | 是 |
依概率收敛与几乎处处收敛
依概率收敛:
“偏离目标的概率越来越小。”
几乎处处收敛:
“对几乎每一条样本路径,最终都会收敛。”
这两句话的主语是不同的:
- 一个在说 概率
- 一个在说 样本路径
二、什么叫“依概率收敛”——你到底在看什么?
定义(先不纠结公式)
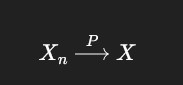
意思是:
对任意一个你能接受的误差 ε>0
“Xn 离 X 超过 ε” 这件事发生的概率 → 0
关键不是 每一次,而是 发生的概率。
用一句话翻译定义
- 并不保证每次实验都接近
- 只保证“大多数时候接近,而且不接近的情况越来越少”
三、什么叫“几乎处处收敛”——你到底在看什么?
定义直观翻译
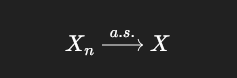
意思是:
对几乎所有样本点 ω,数列 Xn(ω) 最终真的收敛到 X(ω)
这里强调的是:
- 一条一条样本路径
- 不是概率大小,而是“是否最终稳定”
四、用“抛硬币”打比方(非常重要)
情景
你不断抛硬币,记:Xn=前 n 次正面比例
1️⃣ 依概率收敛在说什么?
对任意 ε>0:
“正面比例偏离 0.5超过 ε的概率 → 0”
含义是:
- 抛得越多
- 大多数实验结果看起来都很接近 0.5
- 但不排除偶尔“偏得很离谱”
2️⃣ 几乎处处收敛在说什么?
对几乎每一个具体抛硬币结果序列:
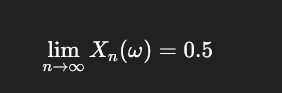
含义是:
- 一旦你的硬币序列固定
- 从某个时刻起,它就一直靠近 0.5
- 再也不会反复大幅偏离
理解样本路径
- 例子:掷骰子每天一次,连续三天
随机变量序列
设:X1=第一天的点数,X2=第二天的点数,X3=第三天的点数
每个 Xn取值 1,2,3,4,5,6 1,2,3,4,5,6 1,2,3,4,5,6
样本空间 Ω
-
所有可能的三天点数组合Ω={(1,1,1),(1,1,2),(1,1,3),…,(6,6,6)}
-
每一个元素都是一个样本点 ω
-
样本空间一共有 6^3=216个样本点
样本点 ω
- 例如选择 ω=(2,5,1)
- 这是一次具体实验的完整结果,记录了三天的点数
样本路径
-
固定这个 ω 后
X1(ω)=2,X2(ω)=5,X3(ω)=1
-
这个数列 (2,5,1)(2,5,1)(2,5,1) 就是样本路径
-
注意:
- 样本路径 = 一条确定的数列
- 它对应一条样本点
- 样本路径 不是所有可能实验的集合,也不是重复实验的平均结果
如果你重复实验
- 每天同样投骰子,但选择了不同的三天结果 ω=(4,3,6)
- 对应的样本路径 = (4,3,6)(4,3,6)(4,3,6)
- 每一个样本路径都是一个 固定实验结果下的序列
核心理解
- 样本空间:所有可能三天点数组合
- 样本点:某一次三天投掷结果
- 样本路径:固定这个结果后,观察 Xn 随 n 的序列
样本路径 = 一条确定的数列,而不是平均、概率或者多次实验的集合。
式子合集
依概率收敛
设随机变量序列 ({Xn}) 收敛到常数a:
说明:
- 固定 ε>0,考察随机变量偏离极限的概率
- 随着 n→∞,偏离概率趋于 0
弱大数定律
设 ==独立同分布随机变量,期望 (E[Xi] = μ)==存在。
定义样本均值:
则:
说明:
- 样本均值依概率收敛到期望(大样本平均值是稳定的,越来越接近真实期望)
- 只保证偏离期望的概率变小
- 不保证每条样本路径都收敛
- 理解:n越多,均值就更加偏向期望
- 当n足够大的时候,可以用期望来代替样本的均值(直接用用总体期望代替大样本均值)
伯努利大数定律
设 (Xi) 为独立的伯努利随机变量:
样本均值为:
则伯努利大数定律表示:
说明:
- 样本均值 = 相对频率
- 随着试验次数 (n→∞),相对频率趋近于理论概率 (p)
- 是弱大数定律的典型应用
计算样本均值期望的推导式子
设独立同分布随机变量 ,样本均值为:
计算样本均值的期望:
说明:
- 样本均值的期望等于单个随机变量的期望
- 样本均值是无偏估计,即长期平均值等于理论期望
中心极限定理
当设 是独立、同分布随机变量,满足:
- 期望:
- 方差:
的前提条件下
则当 时,标准化后的样本均值趋近标准正态分布:
- 表示依分布收敛(收敛到正态分布)
- 标准化:减去期望 ,除以标准差
理解:当n足够多的时候,其样本的均值经过标准化后服从于标准正态分布