
20230109 Selenium
简介
原理
Selenium 是一套 Web网站 的程序自动化操作 解决方案。
通过它,我们可以写出自动化程序,像人一样在浏览器里操作web界面。 比如点击界面按钮,在文本框中输入文字 等操作。
而且还能从web界面获取信息。 比如获取 火车、汽车票务信息,招聘网站职位信息,财经网站股票价格信息 等等,然后用程序进行分析处理。
原理
Selenium 的自动化原理是这样的
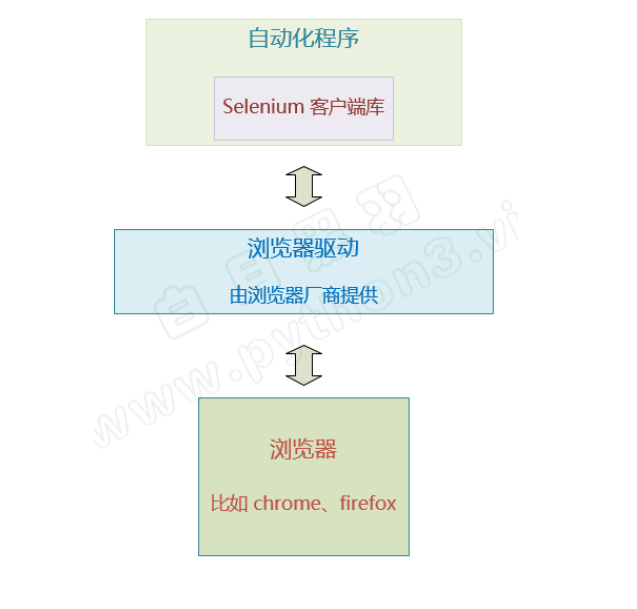
我们再总结一下,selenium 自动化流程如下:
- 自动化程序调用Selenium 客户端库函数(比如点击按钮元素)
- 客户端库会发送Selenium 命令 给浏览器的驱动程序
- 浏览器驱动程序接收到命令后 ,驱动浏览器去执行命令
- 浏览器执行命令
- 浏览器驱动程序获取命令执行的结果,返回给我们自动化程序
- 自动化程序对返回结果进行处理
补充
从上图可以看出:
我们写的自动化程序 需要使用 客户端库。
我们程序的自动化请求都是通过这个库里面的编程接口发送给浏览器。
比如,我们要模拟用户点击界面按钮, 自动化程序里面就应该 调用客户端库相应的函数, 就会发送 点击元素 的请求给 下方的 浏览器驱动。 然后,浏览器驱动再转发这个请求给浏览器。
这个自动化程序发送给浏览器驱动的请求 是HTTP请求。
客户端库从哪里来的? 是Selenium组织提供的。
Selenium组织提供了多种 编程语言的Selenium客户端库, 包括 java,python,js, ruby等,方便不同编程语言的开发者使用。
我们只需要安装好客户端库,调用这些库,就可以发出自动化请求给浏览器咯。
浏览器驱动 也是一个独立的程序,是由浏览器厂商提供的, 不同的浏览器需要不同的浏览器驱动。 比如 Chrome浏览器和 火狐浏览器有 各自不同的驱动程序。
浏览器驱动接收到我们的自动化程序发送的界面操作请求后,会转发请求给浏览器, 让浏览器去执行对应的自动化操作。
浏览器执行完操作后,会将自动化的结果返回给浏览器驱动, 浏览器驱动再通过HTTP响应的消息返回给我们的自动化程序的客户端库。
自动化程序的客户端库 接收到响应后,将结果转化为
数据对象返回给 我们的代码。我们的程序就可以知道这次自动化操作的结果如何了。
安装
Selenium环境的安装主要就是安装两样东西: 客户端库 和 浏览器 驱动 。
https://www.byhy.net/tut/auto/selenium/01/
驱动下载(要和浏览器版本号对应):https://chromedriver.storage.googleapis.com/index.html?path=101.0.4951.41/
加载代码
- 注:Linux用的是/分隔符,而Windows才用的是\
1 | # 驱动路径设置 |
os.path.abspath
- 获取当前目录的绝对路径
2
3
4
5
6
7
8
9
10
11
12
13
14
# 用例补充
import os
print(os.path.abspath(".")) #当前目录的绝对路径
print(os.path.abspath(r"..")) #上级目录的绝对路径
print(os.path.abspath(r"D:\python_workshop\python6\revise\函数.py"))
os.path.join()
os.path.join()函数用于路径拼接文件路径,可以传入多个路径。
- 从后往前看,会从第一个以”/”开头的参数开始拼接,之前的参数全部丢弃;
- 以上一种情况为先。在上一种情况确保情况下,若出现”./”开头的参数,会从”./”开头的参数的前面参数全部保留;
1 | import os |
-
果最后一个组件为空,则生成的路径以一个’/’分隔符结尾 ;
输出:
-
import os
Path1 = ‘home’
Path2 = ‘develop’
Path3 = ‘’Path10 = Path1 + Path2 + Path3
Path20 = os.path.join(Path1, Path2, Path3)
Path30 = os.path.join(Path2, Path1, Path3)
print('Path10 = ',Path10)
print('Path20 = ',Path20)
Path10 = homedevelop
Path20 = home\develop\
-
-
os.path.join()的功能只是起到连接文件的作用,而不能生成文件,如果执行这条语句之后就想生成一个目录或者文件名,可以用:os.mkdir(os.path.join("F:", “test.txt”))
os.path.join(os.getcwd(),‘data’)是获取当前目录,并组合成新目录 -
————————————————
版权声明:本文为CSDN博主「MclarenSenna」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/MclarenSenna/article/details/117046027
爬虫应用
原理
- 调用selenium选择元素并且利用相关函数实现基本操作
对于百度搜索页面,如果我们想自动化输入 白月黑羽 ,怎么做呢?
这就是在网页中,操控界面元素。
web界面自动化,要操控元素,首先需要 选择 界面元素 ,或者说 定位 界面元素
就是 先告诉浏览器,你要操作 哪个 界面元素, 让它找到你要操作的界面元素。
我们必须要让浏览器 先找到元素,然后,才能操作元素。
常见的基本操作如下:
- 点击元素
- 在元素中输入字符串,通常是对输入框这样的元素
- 获取元素包含的信息,比如文本内容,元素的属性
https://www.byhy.net/tut/auto/selenium/03/
选择元素方法
- CSS语法选择元素
- Xpath选择元素(可以比上面的多选择父节点和兄弟节点)
可以安装xpath插件来帮助爬虫内容的筛选
特殊总结
元素存在判断
isEnable()、isDisplayed()和isSelected()
1、以上三个为布尔类型的函数
2、isEnable用于存储input、select等元素的可编辑状态,可以编辑返回true,否则返回false
3、isDisplayed()这个有点陌生,在大神写的脚本看到几次不知道何用意先不管,本身这个函数用于判断某个元素是否存在页面上(这里的存在不是肉眼看到的存在,而是html代码的存在。某些情况元素的visibility为hidden或者display属性为none,我们在页面看不到但是实际是存在页面的一些元素)
4、isSelected(),很显然,这个是判断某个元素是否被选中。例如 页面展示如下: isEnable()、isDisplayed()和isSelected() html代码如下: isEnable()、isDisplayed()和isSelected()