
前言
-
先从最熟悉的东西开始完成自己的开始
-
开始吧
-
本书是介绍如何使用C11多线程来编写并发程序,及相关的语言特性和库工具(library facilities)。本书以“解释并发和多线程的含义,为什么要使用并发”作为起始点,在对“什么情况下不使用并发”进行阐述之后,将对C支持的并发方式进行概述;
最后,以一个简单的C并发实例结束这一章。资深的多线程开发人员可以跳过前面的小节。在后面的几个章节中,会有更多的例子,以便大家对库工具进行更加深入的了解。本书最后,将会给出所有多线程与并发相关的C标准库工具的全面参考。
-
看代码的时候先看thread,全部先看thread
目录
前4章,介绍了标准库提供的各种库工具,展示了使用方法。
第5章,涵盖了底层内存模型和原子操作的实际情况,包括原子操作如何对执行顺序进行限制(这章标志着介绍部分的结束)。
第6、7章,开始讨论高级主题,如何使用基本工具去构建复杂的数据结构——第6章是基于锁的数据结构,第7章是无锁数据结构。
第8章,对设计多线程代码给了一些指导意见,覆盖了性能问题和并行算法。
第9章,线程管理——线程池,工作队列和中断操作。
第10章,测试和调试——Bug类型,定位Bug的技巧,以及如何进行测试等等。
附录,包括新的语言特性的简要描述,主要是与多线程相关的特性,以及在第4章中提到的消息传递库的实现细节和C++11线程库的完整的参考。
并发
-
什么是并发,什么场景算是并发?
理解并发你才能够明白我们需要处理什么问题。
计算机领域的并发指的是在单个系统里同时执行多个独立的任务,而非顺序的进行一些活动。
-
并行和并发的区别是什么?
总结
并发是伪并 并发只有一个处理器
并行是真并 并行有多个处理器
一:
并发是指一个处理器同时处理多个任务。
并行是指多个处理器或者是多核的处理器同时处理多个不同的任务。
并发是逻辑上的同时发生(simultaneous),而并行是物理上的同时发生。
来个比喻:并发是一个人同时吃三个馒头,而并行是三个人同时吃三个馒头。
二:
并行(parallel):指在同一时刻,有多条指令在多个处理器上同时执行。
就好像两个人各拿一把铁锨在挖坑,一小时后,每人一个大坑。所以无论从微观还是从宏观来看,二者都是一起执行的。

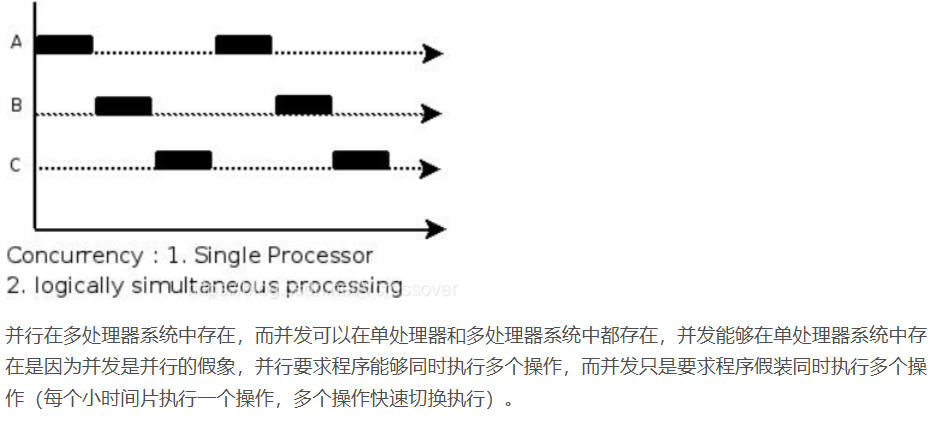
三
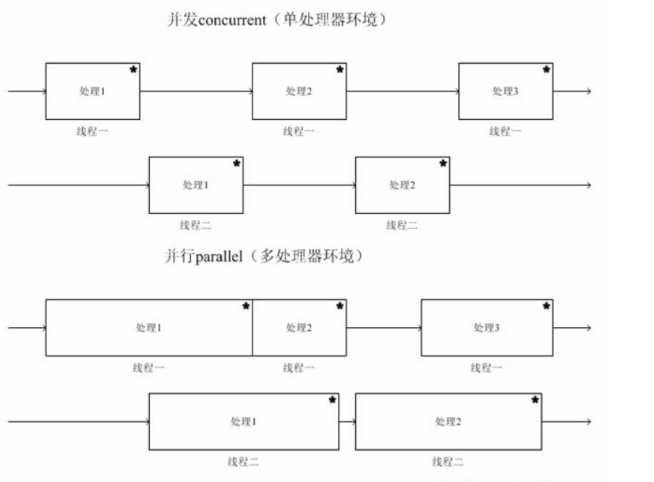
当有多个线程在操作时,如果系统只有一个CPU,则它根本不可能真正同时进行一个以上的线程,它只能把CPU运行时间划分成若干个时间段,再将时间段分配给各个线程执行,在一个时间段的线程代码运行时,其它线程处于挂起状态.这种方式我们称之为并发(Concurrent)。
当系统有一个以上CPU时,则线程的操作有可能非并发.当一个CPU执行一个线程时,另一个CPU可以执行另一个线程,两个线程互不抢占CPU资源,可以同时进行,这种方式我们称之为并行(Parallel)。
为什么需要使用并发?
-
使用并发分离不同的功能区域:一个线程可以处理“用户界面”事件,另一个进行“DVD播放”。它们之间会有交互(用户点击“暂停”),不过任务间需要人为的进行关联。
-
提高性能:
1.第一,将一个单个任务分成几部分,且各自并行运行,从而降低总运行时间。这就是任务并行(task parallelism)。虽然这听起来很直观,但它是一个相当复杂的过程,因为在各个部分之间可能存在着依赖。
2.区别可能是在过程方面——一个线程执行算法的一部分,而另一个线程执行算法的另一个部分——或是在数据方面——每个线程在不同的数据部分上执行相同的操作(第二种方式)。(数据并行)
1.易并行算法具有良好的可扩展特性——当可用硬件线程的数量增加时,算法的并行性也会随之增加。这种算法能很好的体现人多力量大。(?看不懂)
2.通过对多组数据同时执行相同的操作。例如,可以并行处理图片的各部分,就能提高视频的分辨率。
什么时候不使用并发
基本上,不使用并发的唯一原因就是,收益比不上成本。
收益:性能、可维护性、可拓展性、更清晰的代码分离点
成本:分析并发的脑力成本、所需的额外的开发时间以及与维护多线程代码相关的额外成本。此外,线程是有限的资源。如果让太多的线程同时运行,则会消耗很多操作系统资源,从而使得操作系统整体上运行得更加缓慢。
启动线程的注意事项
//√
1 | class background_task |
//×
1 | std::thread my_thread(background_task()); |
//√
1 | std::thread my_thread((background_task())); // 1 |
//√
1 | std::thread my_thread([]{ |
RALL

当线程执行到④处时,局部对象就要被逆序销毁了。因此,thread_guard对象g是第一个被销毁的,这时线程在析构函数中被加入②到原始线程中。即使do_something_in_current_thread抛出一个异常,这个销毁依旧会发生。
观察这个机制,在主线程结束前,thread_guard必然会将进行线程的join操作
joinable()这很重要,因为join()只能对给定的对象调用一次。
拷贝构造函数和拷贝赋值操作被标记为
=delete③,是为了不让编译器自动生成它们。直接对一个对象进行拷贝或赋值是危险的,因为这可能会弄丢已经加入的线程。通过删除声明,任何尝试给thread_guard对象赋值的操作都会引发一个编译错误。如果不想等待线程结束,可以_分离_(_detaching)线程,从而避免_异常安全*(exception-safety)问题。不过,这就打破了线程与
std::thread对象的联系,即使线程仍然在后台运行着,分离操作也能确保std::terminate()在std::thread对象销毁才被调用。
守护线程
-
分离线程/守护线程_(daemon threads),UNIX中守护线程是指,没有任何显式的用户接口,并在后台运行的线程。
-
相应的
std::thread对象就与实际执行的线程无关了,并且这个线程也无法加入
std::thread t(do_background_work);
t.detach();
assert(!t.joinable());
为了从std::thread对象中分离线程(前提是有可进行分离的线程),不能对没有执行线程的std::thread对象使用detach(),也是join()的使用条件,并且要用同样的方式进行检查——当std::thread对象使用t.joinable()返回的是true,就可以使用t.detach()。
试想如何能让一个文字处理应用同时编辑多个文档。无论是用户界面,还是在内部应用内部进行,都有很多的解决方法。虽然,这些窗口看起来是完全独立的,每个窗口都有自己独立的菜单选项,但他们却运行在同一个应用实例中。一种内部处理方式是,让每个文档处理窗口拥有自己的线程;每个线程运行同样的的代码,并隔离不同窗口处理的数据。如此这般,打开一个文档就要启动一个新线程。因为是对独立的文档进行操作,所以没有必要等待其他线程完成。
因此,这里就可以让文档处理窗口运行在分离的线程上。
1 | void edit_document(std::string const& filename) |
假设我同时编辑试图在两个不同的线程中操作相同的文件
要么在开启线程之前就应该判断操作的是否是相同的东西
要么就设置互斥锁之类的吧
线程传递参数
在多线程编程中向线程函数传递参数是一个常见的需求。本文讨论了几种不同场景下传递参数的方式及其注意事项,并提出了相应的解决方案。
-
传引用
-
参数的类型转化
-
传递函数指针、函数对象
-
传递unique_ptr
-
传递share_ptr
-
关于上面两个指针的线程安全问题和访问权限的问题
转移线程所有权
- 对象名本身是一个壳子:移动语义在不同的
std::thread对象之间转移线程的所有权 - 函数的返回值或参数,通过移动语义在函数间传递。
scoped_thread类确保线程在其作用域结束时完成- 应用:自动化管理大量线程
std::thread支持移动,但不支持拷贝
线程数量的获取与应用
概述
使用并行算法可以显著提升计算性能,特别是在多核系统中。 C++11引入的 std::thread和 std::thread::hardware_concurrency()提供了便捷的工具来编写并行算法。以下将介绍如何实现一个并行版本的std::accumulate。
代码示例
下面的代码展示了如何实现一个并行版的std::accumulate。它将整体工作拆分成小任务,并分配给多个线程执行,最终合并结果。
1 | template<typename Iterator, typename T> |
这个结构体定义了一个可调用对象,用于计算一段范围内的累加值。
并行累加函数 parallel_accumulate:
1 | template<typename Iterator, typename T> |
该函数接收一个迭代器范围和初始值init,将范围分成多个块,每个块由一个线程处理。计算出的中间结果存储在results向量中,最后通过std::accumulate将中间结果合并。
主函数测试并行累加:
1 | int main() { |
- 在主函数中创建了一个包含10000个1的向量,并调用
parallel_accumulate计算其总和。
结论
通过使用std::thread::hardware_concurrency()确定适合的线程数量,可以有效地将工作分配给多个线程执行,从而提升并行计算的性能。parallel_accumulate展示了如何实现一个简单的并行算法,同时处理好线程的创建、执行和结果合并。
线程id
- 获取方式有两种
- 线程库提供的对比操作
- 应用:同样,作为线程和本地存储不适配的替代方案,线程ID在容器中可作为键值。例如,容器可以存储其掌控下每个线程的信息,或在多个线程中互传信息。
线程间数据共享的问题
-
问题可能场景:
1.当线程在访问共享数据的时候
2.一个线程更新了共享数据