
C++Primer快速回顾
复习思路
- 不用一章一章看看,这段时间遇到的问题,当你看到这个目录的时候,想到的问题,感兴趣的问题都可以看,你看知识的目的是为了解决问题,不是纯粹背诵概念,你要明白这一点。
看目录想问题
- C++语言的三大特性以及相关的代码体现,这样做有什么优点和缺点
- 一个C++程序从编写编译到运行的过程
- 要你自己实现一个字符串的类你要怎样设计拷贝、赋值、析构函数
- C++是怎样来管理内存的,和java有什么区别和联系
- C11、C14的关键新特性有什么
- using namespace std,解释一下这句话
- 虚基类是什么?底层是怎样实现的?
- C++一般的作用域规则是什么?
- C++的const你要怎样区分和分辨
- 强制类型转换中可能会出现什么样的错误?
- lambda、函数对象是怎么一回事?
- 函数模板能干什么?
一些次级问题和主观感受
- 感觉写代码就是符合规范写东西,试图在某个时机把一个东西从一个地方传另一个地方并且能够保证被合理的使用
C++三大特性
-
C++语言的三大特性?相关的代码体现?代码实现?这样做有什么优点和缺点 ?和其他的类比?
-
其实最大的问题不是你记得了什么,而是你是怎样思考的,现在我的思考范式是什么呢?
我有一个功能,我需要实现它,我需要一段在框架之下的符合逻辑代码
我有一个框架,我需要代码来理解它
我有一个东西,你想要理解,我找比喻来给你解释,或者是拿基础的东西来给你解释
类比
优化
底层
彼此之间到底有什么层次和环节
不同抽象层次之间的底层到底是什么
从代码(函数,数据,类和对象)到寄存器
从一个端口到另一个端口
从一个ip到另一个ip
函数的实现判断和边界是什么
实现这一个功能调动了多少资源
内存如何被管理
是否有一个合理的评估标准和判断标准
三大特性定义
定义
1.封装 :封装是将数据和操作数据的方法捆绑在一起的机制,以防止外部对数据的直接访问。 在C++中,封装通常通过类来实现,将数据成员私有化,通过公有成员函数提供对数据的访问和操作。
2.继承 :继承是指一个类可以基于另一个类而创建的机制,新创建的类可以继承基类的属性和方法,并且可以添加新的成员或者重写已有的成员函数。
3.多态 :多态是指同一操作在不同对象上具有不同的行为的能力。
在C++中,多态通过虚函数和函数重写来实现。子类可以重写基类的虚函数,当通过基类指针或引用调用这个函数时,根据指针或引用所指向的具体对象的类型,会调用对应的子类函数。
三大特性优缺点
封装
封闭起来,包起来,实现隐藏
通过类来实现
不仅将私有数据封闭起来,也将方法的具体实现隐藏起来
修改类的内部不会影响外部
隐藏了方法的实现细节,提高了安全性,代码更方便读和规范
优点:
- 提高了代码的可维护性和可重用性,因为修改类的内部实现不会影响外部用户。
- 隐藏了数据的实现细节,提高了安全性,避免了数据被不合理地
缺点:
- 需要编写额外的公有成员函数来访问和操作私有数据,增加了代码量和复杂性。
- 有时候 过度的封装可能会导致性能损失,因为需要通过函数调用来访问数据。
继承
提高代码的复用性
建立类的层次,能够更好管理类
优点:
- 提高了代码的可重用性,可以在不修改基类代码的情况下扩展类的功能。
- 通过建立类的层次结构,可以更好地组织和管理代码,提高了代码的可维护性。
缺点:
- 可能导致类之间的耦合性增加,增加了代码的复杂性。
- 如果不正确使用,可能会导致继承层次结构混乱,难以理解和
多态
实现动态绑定
- 提高了代码的灵活性和可扩展性,允许以通用的方式操作对象,而不需要知道对象的具体类型。
- 可以在运行时动态确定调用哪个函数,实现了动态绑定,提高了代码的可扩展性。
缺点:
如果过度使用,可能会导致代码难以理解和调试,降低代码的可维护性- 使用虚函数会带来一定的运行时开销
三大特性的具体实现
-
封装:类
-
继承:子类父类
-
多态:虚函数和函数重写(调用和重写双方面来实现多态的)
简而言之就是用父类型别的指针指向其子类的实例,然后通过父类的指针调用了子类的成员函数。这种技术可以让父类的指针有“多种形态”。这种类型的识别是在程序运行时定义的,也叫运行时多态。
虚函数/暗含继承
定义
父类中允许子类重写的类
在 C++ 中,只有==公有继承(public inheritance)==才能实现虚函数的重写(覆盖)。如果使用私有继承(private inheritance)或保护继承(protected inheritance),则无法重写父类中的虚函数。
×
#include
using namespace std;class father
{
int num;
public:
virtual void printNum()
{
cout << “father” << num << endl;
}};
class son:private father
{
public:
void printNum()override
{
cout << “son” << endl;
}
};int main()
{
father u;
son k;u.printNum(); k.printNum(); return 0;}
编译通过
并且能够正常运行
具体实现
虚函数的实现是由两个部分组成的,虚函数指针与虚函数表。
2.1 虚函数指针
为了指定对象的虚表,对象内部包含一个虚表的指针,来指向自己所使用的虚表。为了让每个包含虚表的类的对象都拥有一个虚表指针,编译器在类中添加了一个私有指针,*__vptr,用来指向虚表。
这样,当类的对象在创建时便拥有了这个指针,且这个指针的值会自动被设置为指向类的虚表。
只有拥有虚函数的类才会拥有虚函数指针,所以拥有虚函数的类的所有对象都会因为虚函数产生额外的开销,并且也会在一定程度上降低程序速度。与JAVA不同,C++将是否使用虚函数这一权利交给了开发者,所以开发者应该谨慎的使用。

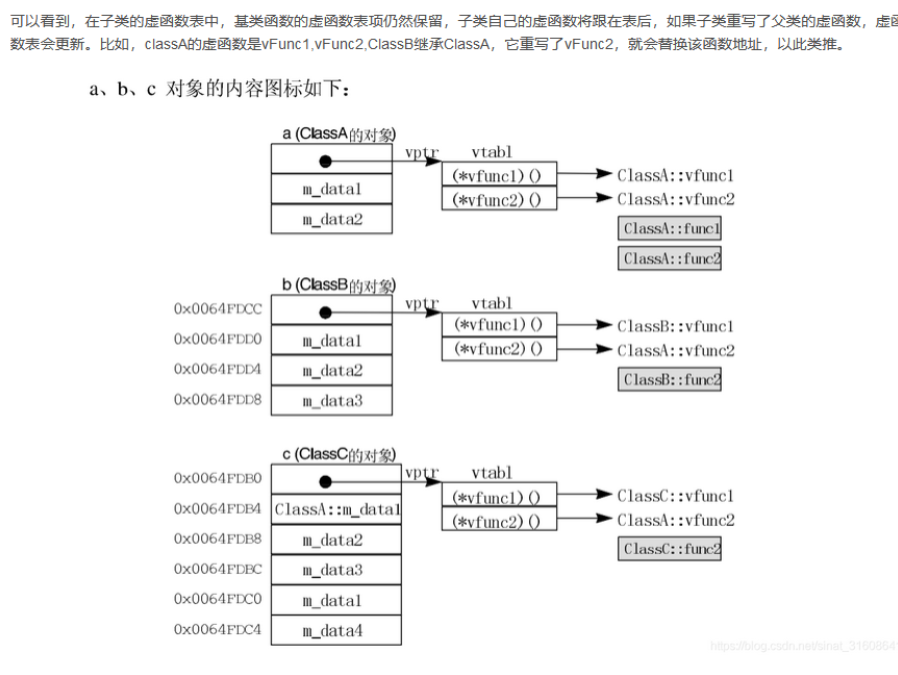
自己尝试理解这张图:
同一个类的对象所拥有虚指针是相同的,且所拥有的虚指针所指向的表也是相同的
2.2 虚函数表
虚函数表是一个类的虚函数的地址表,用于索引类本身以及父类的虚函数的地址,假如子类的虚函数重写了父类的虚函数,则对应在虚函数表中会把对应的虚函数替换为子类的 虚函数的地址;
虚函数表指针存在于每个对象中(通常出于效率考虑,会放在对象的开始地址处), 它指向对象所在类的虚函数表的地址;在多继承环境下,会存在多个虚函数表指针,分别指向对应 不同基类的虚函数表。
虚表是属于类的,对于基类与派生类,基类有基类的虚函数表,派生类有派生类的虚函数表。
不同类的对象所拥有的虚指针是不同的
存在继承关系的类的虚函数指针关系和虚表关系是怎么样的呢?
有重叠的部分吗?
举个例子,定义三个类A,B,C依次继承
1 | class ClassA |
如果想要观察的话最好就是获取虚指针,观察其所指向的内容的对应索引们的位置和对应的函数代码存储的位置是否相同
三、一些遗留问题
1、 构造函数是否能为虚函数?
不能,
1)如果构造函数是虚函数,那么就需要通过虚表指针vtable 来调用,但此时面对一块没有初始化的内存,到哪里去找 vtable 呢?毕竟,vtable 是在构造函数中才初始化的啊,而不是在其之前。因此构造函数不能为虚函数。
2)构造函数在进行调用时还不存在父类和子类的概念,父类只会调用父类的构造函数,子类调用子类 的,因此不存在动态绑定的概念
2、析构函数可以是虚函数吗?
可以,而且最好是虚的,因为此时 vtable 已经初始化了;况且我们通常通过基类的指针来销毁对象,如果析构函数不为虚的话,就不能正确识别对象类型,从而不能正确销毁对象。
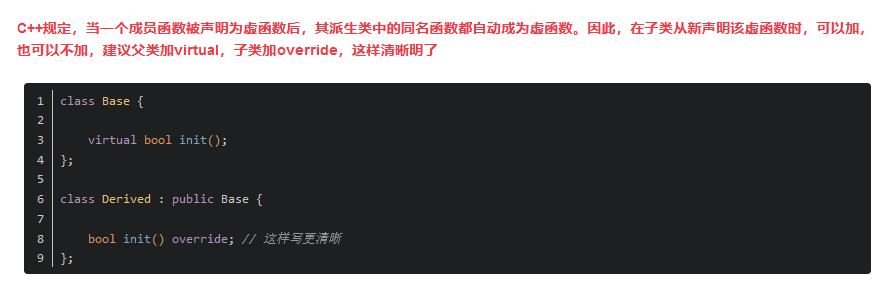
3、使用虚函数的时候,子类也要使用virtual关键字吗?
父类使用虚函数是为了让子类重写,那子类重写的时候也需要带virtual关键字吗?比如:
4、构造函数中可以调用虚函数吗?
可以,但是没有动态绑定的效果,父类构造函数中调用的仍然是父类版本的函数,子类中调用的仍然是子类版本的函数
5、内联函数、静态成员函数可以是虚函数吗?(看到虚函数的运行实现时机和其他机制的实现时机是不一样的)
内联函数可以,但是不要这么写。内联函数需要在编译阶段展开,而虚函数是运行时动态绑定的,编译时无法展开,当然你可以写 inline virtual 这样的函数,它也不报错,因为内联是编译器决定的,并不跟是否有关键字inline有关系。而虚函数的多态性在运行期,编译器无法知道运行期调用哪个代码,因此虚函数表现为多态性时(运行期)不可以内联;
静态成员函数不可以,因为它是以类为单位的函数,与具体对象无关,无this指针,虚函数是与对象动态绑定的,必定是成员函数,成员函数肯定有this指针,因此是两个冲突的概念;
https://blog.csdn.net/sinat_31608641/article/details/104801425
睡觉
…
内联函数的实现
https://blog.csdn.net/qq_35902025/article/details/127912415
基本问题思路:
什么是内联函数
为什么需要使用内联函数
什么是内联函数
1.直观上定义:
联函数的定义与普通函数基本相同,只是在函数定义前加上关键字 inline。
1 | inline void print(char *s) |
2.更深入的思考:
- 函数前面加上inline一定会有效果吗?
- 如果不加inline就不是内联函数了吗?
后面让我们慢慢来解答这两个问题
为什么使用内联函数
- *内联函数最初的目的:代替部分 #define 宏定义;
- 使用内联函数替代普通函数的目的:提高程序的运行效率;
针对上述两个方面我们展开讨论
1.为什么要代替部分宏定义
宏是预处理指令,在预处理的时候把所有的宏名用宏体来替换;
内联函数是函数,在编译阶段把所有调用内联函数的地方把内联函数插入;
宏没有类型检查,无论对还是错都是直接替换;
而内联函数在编译时进行安全检查;
宏的编写有很多限制,例如只能写一行,不能使用return控制流程等;
对于C++ 而言,使用宏代码还有另一种缺点:无法操作类的私有数据成员。
2.普通函数频繁调用的过程消耗栈空间
函数是一个可以重复使用的代码块,CPU 会一条一条地挨着执行其中的代码。CPU 在执行主调函数代码时如果遇到了被调函数,主调函数就会暂停,CPU 转而执行被调函数的代码;被调函数执行完毕后再返回到主调函数,主调函数根据刚才的状态继续往下执行。
一个 C/C++程序的执行过程可以认为是多个函数之间的相互调用过程,它们形成了一个或简单或复杂的调用链条,这个链条的起点是main(),终点也是main()。当main()调用完了所有的函数,它会返回一个值(例如return 0;)来结束自己的生命,从而结束整个程序。
函数调用是有时间和空间开销的。程序在执行一个函数之前需要做一些准备工作,要将实参、局部变量、返回地址以及若干寄存器都压入栈中,然后才能执行函数体中的代码;函数体中的代码执行完毕后还要清理现场,将之前压入栈中的数据都出栈,才能接着执行函数调用位置以后的代码。
数据和函数都压入栈,执行代码,执行完毕后要清理现场/实现出栈
栈空间就是指放置程式的局部数据也就是函数内数据的内存空间,在系统下,栈空间是有限的,假如频繁大量的使用就会造成因栈空间不足所造成的程式出错的问题,函数的死循环递归调用的最终结果就是导致栈内存空间枯竭。
如果函数体代码比较多,需要较长的执行时间,那么函数调用机制占用的时间可以忽略;
如果函数只有一两条语句,那么大部分的时间都会花费在函数调用机制上,这种时间开销就就不容忽视。
总结:函数调用机制所产生的开销(栈的空间开销和出栈入栈的时间开销)
为了消除函数调用的时空开销,C++ 提供一种提高效率的方法,即在编译时将函数调用处用函数体替换,类似于C语言中的宏展开。这种在函数调用处直接嵌入函数体的函数称为内联函数(Inline Function)。但也存在缺点,就是每一调用处均会展开,增加了重复的代码量。
可以理解为内联函数的关键词是:替换
展开的关键
3.更深入的思考
通过上述内容我们知道内联函数是在调用的地方展开函数定义,那么问题又来了,展开也好,替换也好,都存在下面两个问题:
- 内联函数一定就会展开吗?
- 在什么情况下内联函数会展开?
三.内联函数和编译过程的相爱相杀
在这一节,我们先一口气回答前两节的所有问题,然后慢慢引出后面的话题。
函数前面加上inline一定会有效果吗
如果不加inline就不是内联函数了吗?
内联函数一定就会展开吗?
在什么情况下内联函数会展开?
关键 inline到底起没起作用/展开与否/效果与否
函数前面加上inline一定会有效果吗
不会,使用内联inline关键字修饰函数只是一种提示,编译器不一定认。
如果不加inline就不是内联函数了吗?
存在隐式内联,不用inline关键字,C++中在类内定义的所有函数都自动称为内联函数。
内联函数一定就会展开吗?
其实和第一个问题类似,还是看编译器认不认。
在什么情况下内联函数会展开?
首先需要满足有inline修饰或者是类中的定义的函数,然后再由编译器决定(关键)。
其实说白了,内联函数管不管用是由编译器说了算的!
那如何要求编译器展开内联函数呢?
1.编译器开优化:gcc -O2 test.c -o test,只有在编译器开启优化选项的时候,才会有inline行为的存在,比如对g++在-O0时就不会作任何的inline处理,对于-O2的优化方式,编译器会通过启发式算法决定是否值得对一个函数进行内联,同时要保证不会对生成文件的大小产生较大影响。 而-O3模式则不在考虑生成文件的大小;
2.使用attribute属性:static inline attribute((always_inline)) int add_i(int a,int b);
3.使用auto_inline:#pragma auto_inline(on/off),当使用#pragma auto_inline(off)指令时,会关闭对函数的inline处理,这时即使在函数前面加了inline指令,也不会对函数进行内联处理。
上述操作都仅仅是对编译器提出内联的建议,最终是否进行内联由编译器自己决定,大多数编译器拒绝它们认为太复杂的内联函数(例如,那些包含循环或者递归的),而且类的构造函数、析构函数和虚函数往往不是内联函数的最佳选择。
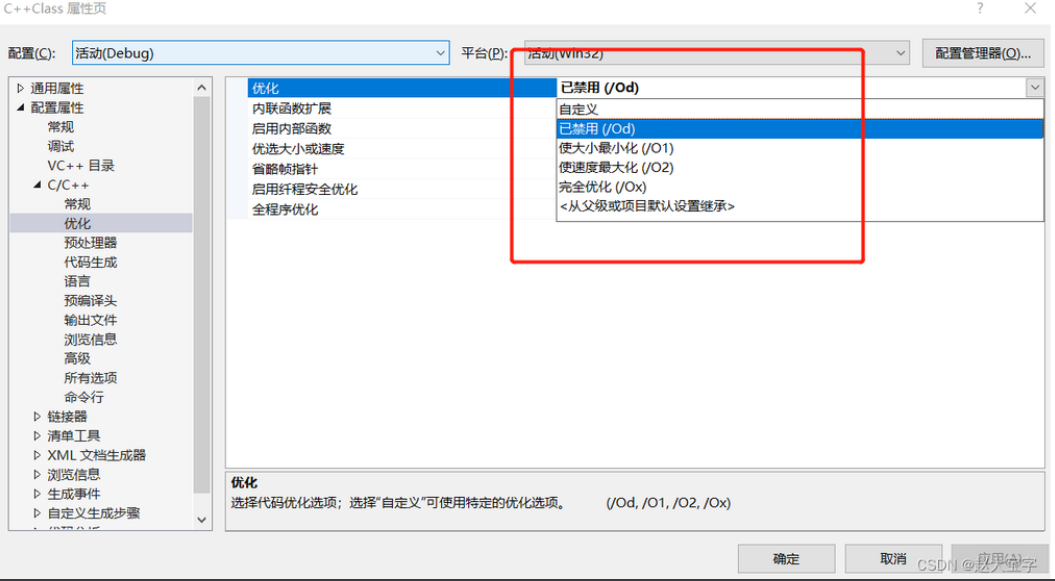
有关visual studio中编译优化选择的位置如图,gcc编译见上面的例子也可以直接man gcc查看。
内联函数怎么用,在哪儿用?
基本介绍完内联的概念,接下来说说内联怎么用,在哪儿用?
内联函数是定义在头文件还是源文件?
内联展开是在编译时进行的,只有链接的时候源文件之间才有关系。
1.所以内联要想跨源文件必须把实现写在头文件里。
2.如果一个内联函数会在多个源文件中被用到,那么必须把它定义在头文件中
3.内联函数的定义不一定要跟声明放在一个头文件里面:
4.定义可以放在一个单独的头文件中,里面需要给函数定义前加上inline 关键字,
这里到底想讲什么
原因看下面第 2.点;然后声明 放在另一个头文件中,此文件include上一个头文件。
这种用法 boost里很常见:优点1. 实现跟API分离封装。优点2. 可以解决有关inline函数的循环调用问题。
1.隐式内联:如第三节说的C++中在类内定义的所有函数都自动称为内联函数,类的成员函数的定义直接写在类的声明中时,不需要inline关键字
1 |
|
2.显式内联:需要使用inline关键字
1 |
|
内联函数和重定义
这一部分我们带着问题一步步进行分析思考
什么是重定义?
答:C/C++语法中,如果变量、函数在同一个工程中被多次定义,链接期间会报类似“对 xxx 多重定义”的错误。
当内联函数的声明和定义分别在头文件和源文件中,并且在其他文件中被调用时,链接期间编译器会报“对 xxx 未定义的引用”错误。内联函数如果会在多处被调用,则需要将函数的定义写在头文件中。
为什么inline关键字修饰的函数定义在头文件中(函数可能会被多次定义),编译器不会报“对 xxx 多重定义”的错误呢?
答:编译器对被inline修饰的函数做了特殊处理,inline起到了内联的作用
inline为什么能起作用?
答:因为inline是一个弱符号;
什么是弱符号?
答:在C语言中,编译器默认函数和初始化了的全局变量为强符号(Strong Symbol),未初始化的全局变量为弱符号(Weak Symbol)。
强符号之所以强,是因为它们拥有确切的数据,变量有值,函数有函数体;弱符号之所以弱,是因为它们还未被初始化,没有确切的数据。
链接器会按照如下的规则处理被多次定义的强符号和弱符号:
-
不允许强符号被多次定义,也即不同的目标文件中不能有同名的强符号;如果有多个强符号,那么链接器会报符号重复定义错误。
-
如果一个符号在某个目标文件中是强符号,在其他文件中是弱符号,那么选择强符号。
-
如果一个符号在所有的目标文件中都是弱符号,那么选择其中占用空间最大的一个。
怎么知道inline是个弱符号的?
答:反汇编:objdump -dS test,看下面两个例子:
下面两个.cpp文件,除Function()的inline修饰符外其他内容完全一致
1.正常的函数
1 | /* NormalMain.cpp */ |
汇编结果 :
1 | .file "NormalMain.cpp" |
…
https://blog.csdn.net/qq_35902025/article/details/127912415
讲到汇编已经开始吐血了
我只想了解到内联函数和C++的关系就好了